HDFS EC存储冷数据
实现成果
- ec文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
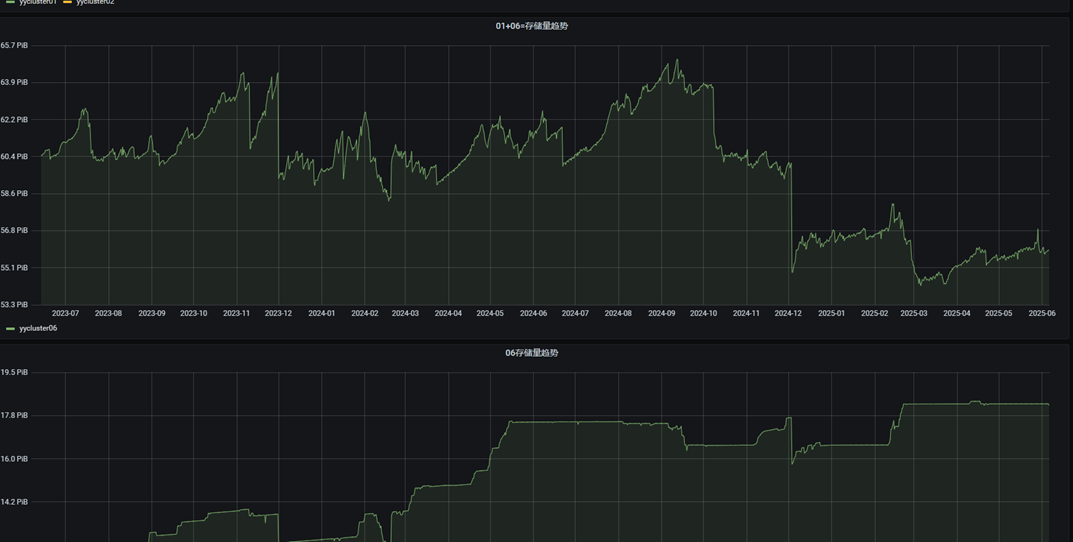
- 成果: 降低20PB+存储空间,可以看到每次数据都有阶段性的存储下降
实现方案
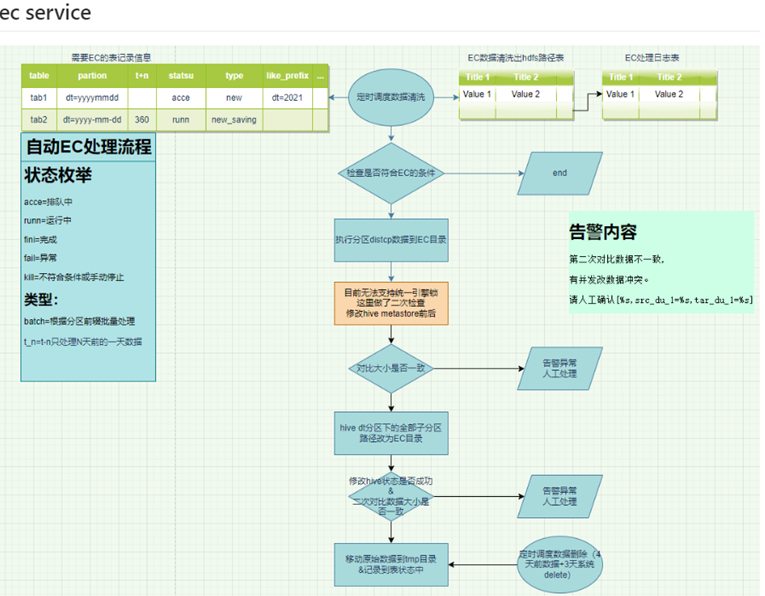
- EC存储流程图设计,这个是最初的设计,现流程有优化改动。
- 为了不影响现有集群,我们单独搭建了独立EC冷存储集群,但yarn计算资源还是统一使用,只是把datanode分开部署。
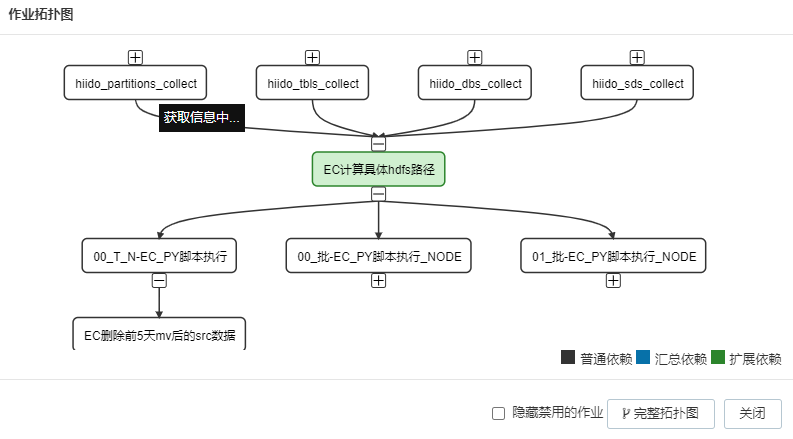
- 调度集成拓扑图
实现逻辑基于python编写,主要是采集到所有表信息,然后对配置表(需要EC转存的信息)进行清洗,比如过滤掉小文件的分区,或时间最近N(可配置)天有改动的分区,对正在EC转存的分区进行锁定hdfs路径,不允许业务改动或删除,会抛出异常提示,人工干预,避免造成脏数据。核对分区大小,文件是否一致等一系列逻辑。
- EC每天转存报表
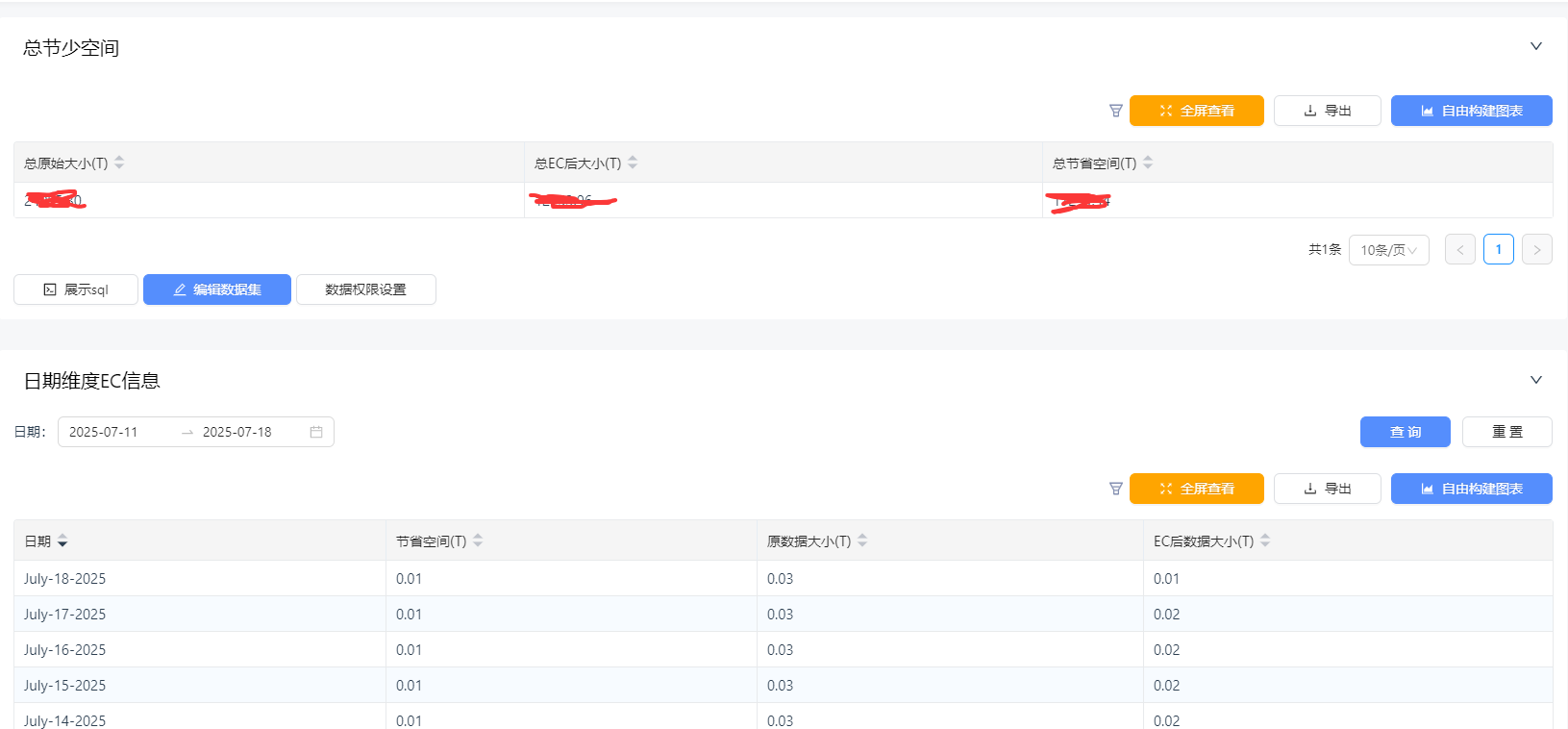
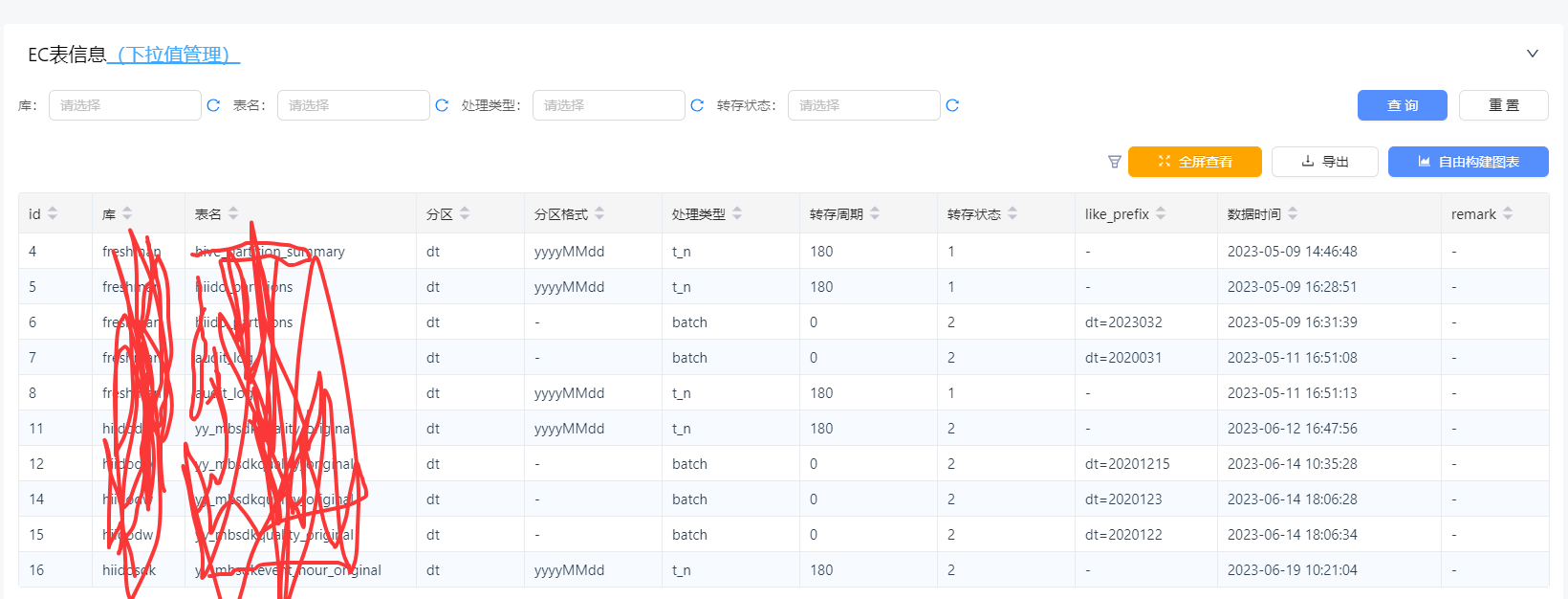
- EC表配置信息
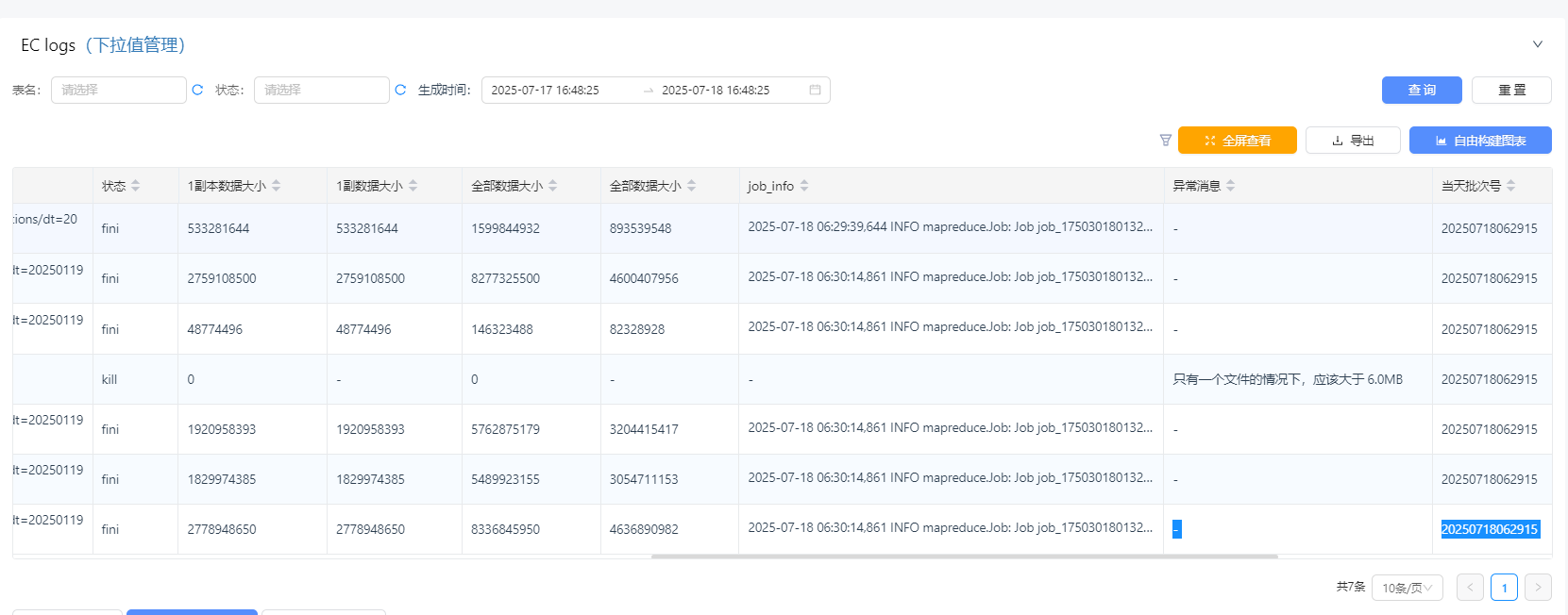
- EC日志 每个分区存储信息都需要记录下来
实现过程中遇到的问题
补丁修复
- 因我们是用hadoop 3.1.1版本做的EC,而EC功能是在hadoop3.0.0中才有的,必然有很多bug,在调研阶段已升级了很多EC path,但在实践过程中,还是遇到了文件损坏的问题,再次修复了大量patch进行升级
-
第一阶段修复 HDFS-16420 1642xx相关 删除冗余条带块时避免删除唯一数据块
HDFS-14859 当 dfs.namenode.safemode.min.datanodes 不为零时,防止对代价高昂的操作 getNumLiveDataNodes 进行不必要的评估
HDFS-14353, 修复 xmitsInProgress 指标异常。
HDFS-14523, 去除 NetworkTopology 多余锁。
HDFS-14849, DN 下线导致 EC 块无限复制。
HDFS-15240, 修复脏缓存导致数据重建错误。
HDFS-16806 balancer bug - 第二阶段再次修复
HDFS EC 文件验证器,这个比较重要,需要开启EC恢复验证:https://github.com/sodonnel/hdfs-ec-validator
当块组最后一个不完整的单元落入 AlignedStripe 时,解码失败:https://issues.apache.org/jira/browse/HDFS-14373
部分 DataNode 关闭时,部分 ORC 数据无法恢复:https://issues.apache.org/jira/browse/HDFS-15085
关于EC会造成错误数据的bug 在实时副本检查中应考虑繁忙的 DN 副本:https://issues.apache.org/jira/browse/HDFS-14768
在某些情况下,退役可能会生成奇偶校验块的内容全为 0 :https://issues.apache.org/jira/browse/HDFS-15186
当源数据节点不足时,NameNode不应发送重建工作 :https://issues.apache.org/jira/browse/HDFS-16479 - 3.4.0 fixed 验证DataNode上EC重构的正确性 :https://issues.apache.org/jira/browse/HDFS-15759
修正了数据节点陈旧时块恢复的错误 :https://issues.apache.org/jira/browse/HDFS-17094
–check https://github.com/apache/hadoop/pull/3593 https://issues.apache.org/jira/browse/HDFS-16286
hdfs debug verifyEC -file /dfsperf.0.0 - 其它修复
Fsck -blockId 显示 EC :https://issues.apache.org/jira/browse/HDFS-14266
blockIndices [i] 调用了错误的索引 :https://issues.apache.org/jira/browse/HDFS-15135
如果 updatePipeline 期间出现异常,文件写入会在关闭期间挂起 :https://issues.apache.org/jira/browse/HDFS-15211
EC 块在故障转移和恢复的情况下被标记为 CORRUPT :https://issues.apache.org/jira/browse/HDFS-15170
脏缓冲区导致重建块错误 :https://issues.apache.org/jira/browse/HDFS-15240
如果一个或多个数据节点在退役期间停止服务,退役可能会挂起 :https://issues.apache.org/jira/browse/HDFS-14920
当复制流硬限制达到阈值时,实时副本中不考虑存储 :https://issues.apache.org/jira/browse/HDFS-14699
内部块丢失并且同时被过度复制 :https://issues.apache.org/jira/browse/HDFS-8881
LOG 中损坏的 ec 块的大小值不正确 :https://issues.apache.org/jira/browse/HDFS-14808
损坏文件处理
- 我们之前只做了在转存时验证,没有做EC重构验证,这个已拉取补丁修复,但我们还是会定期全量EC检查文件验效码(hdfs默认文件的CRC32),这里做的再严谨一点,是对比每个文件块的元数据验校。同时会收集群据dn重构EC日志,每天去做验证是否损坏。
-
损坏原因 是因为机器混部署了其它人的服务,而其它人服务是在灰度验证阶段,导致大量机器网络有问题,但这个问题又没有明显暴露出来,机器不断失去心跳,导致数据不断重构,后面我们加入了大量监控,并且启用了严格的维护模式配置,节点StaleDataNodes日志输出,并指标监控告警,和活跃节点数有变动告警。 虽然是其它服务影响,但hdfs EC 确实存在重大bug,只是机率大小问题,在退役过程中也会存在导致文件损坏的BUG,所以要使用hdfs EC 至少在3.3.0版本之上用,并且要开启重构块验证功能。
- 对已经损坏的文件做恢复
第一种情况:只有一个节点或二个节点的块损坏,我们是用的RS-3-2-1024k策略,其它的以此类推, 我们重写了hdfs客户端代码,来会屏蔽读取损坏的块,来for持续恢读取EC正常块的数据,再结合具体文件做验证,比如ORC parquet是否是一个合法的文件,如果是则读取出来,进行重写文件,然后进行覆盖坏文件,如果是txt我们结果表字段数来验证是否是合法文件,如果是损坏的文件,大多列是乱码,只有1-2列。
具体代码参考:https://github.com/liangrui1988/hadoop-client-op/blob/main/src/main/java/com/yy/bigdata/orc/OpenFileLine.java
hdfs客户端代码修改的部分在hadoop源码,不便于展示。 - 还有一个问题,就是如果一个datanode上存在2个同一文件的块,是无法自动清除的,社区没有回复,目前是通过自已写的Python服务清除,具体问题详见: https://issues.apache.org/jira/browse/HDFS-17589
后续监控和检查
文件检查
1:把所有EC文件的CRC校验码记录到mysql中,一周全量对比一次,根据情况而定,如果发现crc有变化,说明文件EC有过重构并异常,需要人工确认,再安全一点的做法是进行文件块进行验证对比。
2:对重构过的EC文件,通过dn日志收集,然后用EC自带的验证工具进行验证,是否正常。
例: hdfs --config /etc/hadoop/06_conf debug verifyEC -file /hive_warehouse/xx.db/xx/dt=20191003/xx
一些诊断文件的语句例子:
# 通过块找到文件
hdfs fsck -fs hdfs://yyclusterxx -blockId blk_-9223372036044793952
# 验证文件
hdfs --config /etc/hadoop/06_conf debug verifyEC -file /hive_warehouse/xx.db/xx/dt=20191003/xx
# 通过文件找到节点信息
hdfs fsck -fs hdfs://yycluster06 /hive_warehouse/pub_dw.db/pub_dwv_event_comm_ret_detail_di/dt=2022-08-14/data_type=PC/part-01114-d4289994-dcf9-4292-9e73-d31218ef3e2d.c000 -files -blocks -locations
# 通过节点找到物理文件
ll /data*/hadoop/hdfs/data/current/BP-1099381363-10.12.xx.xx-1704271160327/current/finalized/subdir*/subdir*/blk_-922337203604479395*
文件恢复
注:文件恢复的实现是自己更改了hdfs客户端代码,实现不断重试好的文件块节点,发现有坏的就skip过,验验方式结合文件格式验证和文件内容的格式验证来判断是否好的块。
如果坏块超出可恢复的节点限制,则文件彻底损坏,无法进行恢复。
参考代码:https://github.com/liangrui1988/hadoop-client-op
# 文件恢复的例子,txt gzip压缩
hadoop jar hdfs-client-op-1.0-SNAPSHOT.jar com.yy.bigdata.utils.TextCheck /hive_warehouse/yydw.db/dwv_event_detail_mob_quality_day/dt=2021-07-02/product_id=171/part-00067-5b19f0ff-dfb5-420f-9f93-3b059335bcae.c000.gz gzip
# orc 格式恢复
hadoop jar hdfs-client-op-1.0-SNAPSHOT.jar com.yy.bigdata.orc.OpenFileLineSigle /hive_warehouse/yule.db/yule_new_subscribe_list_day/dt=20191003/002371_0 orc
# parquet
hadoop jar hdfs-client-op-1.0-SNAPSHOT.jar com.yy.bigdata.orc.OpenFileLineSigle /hive_warehouse/xx.db/xx/dt=20191003/xx parquet