YARN超卖内存实现
实现YARN内存超卖配置后的成果
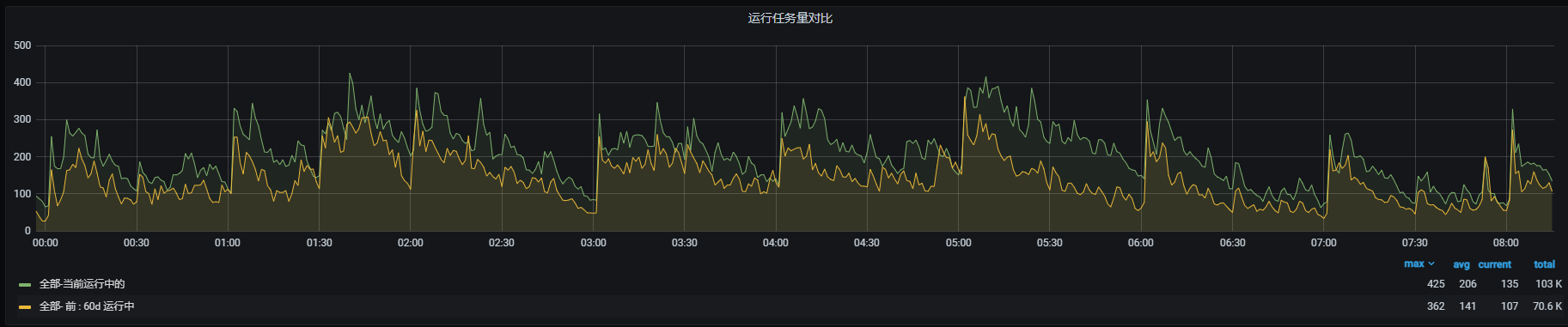
提升集群内存利用率15%,超卖内存20TB+的实践
效果对比
启用cgroup来监控内存后,对比nodemanger服务器,nm JVM堆内存效率提升,GC时长和GC次数明显降低
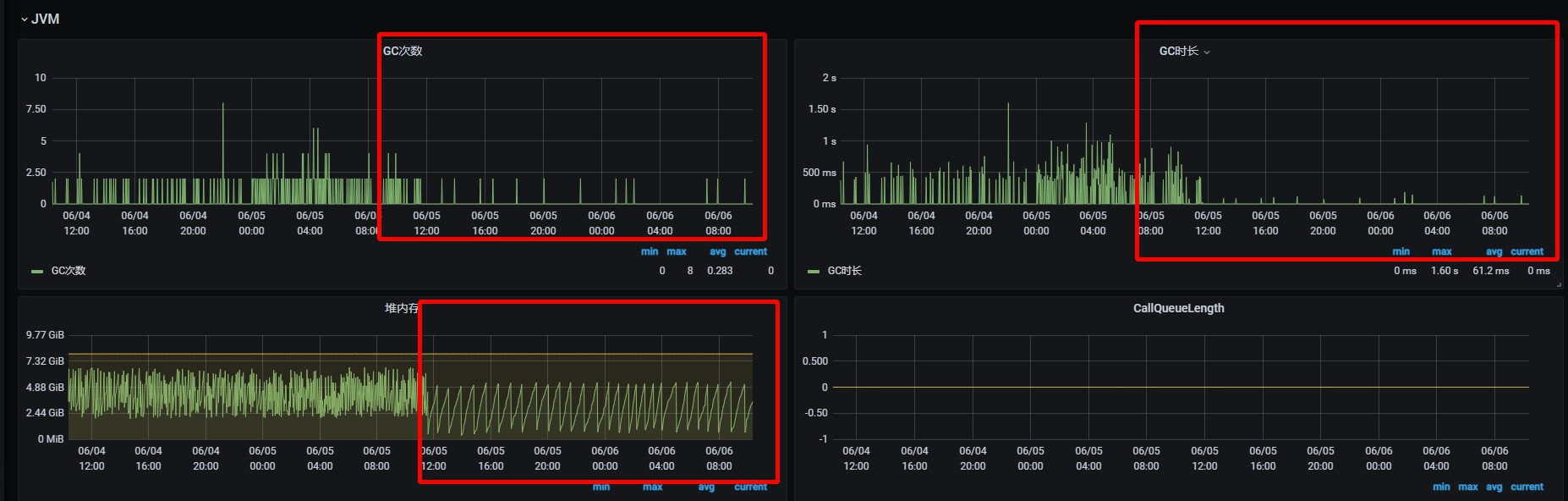 观察到nm升级为cgroups管理内存后,整个堆内存应用降低很多,可以把nm内存降低2G,(8-2=6G),并把这2G给到yarn分配使用。 例:ys13_7调整后的效果
观察到nm升级为cgroups管理内存后,整个堆内存应用降低很多,可以把nm内存降低2G,(8-2=6G),并把这2G给到yarn分配使用。 例:ys13_7调整后的效果
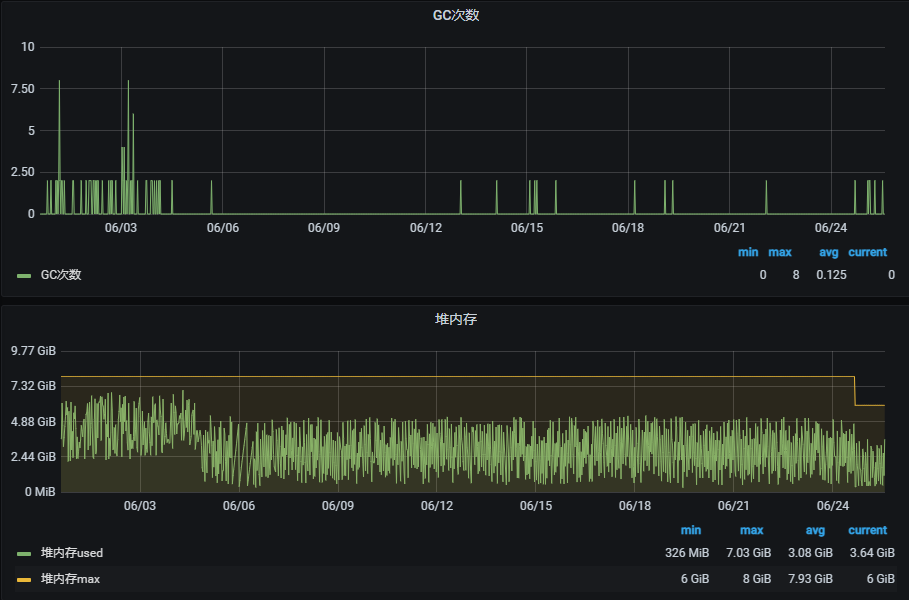
原101G+15=116G,超卖15G | cgroups限制内存为:103G
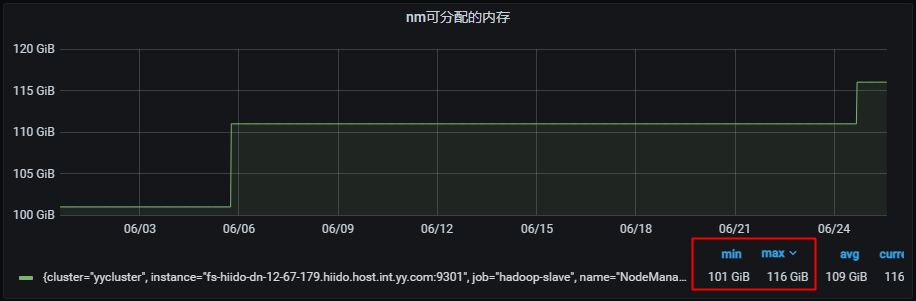
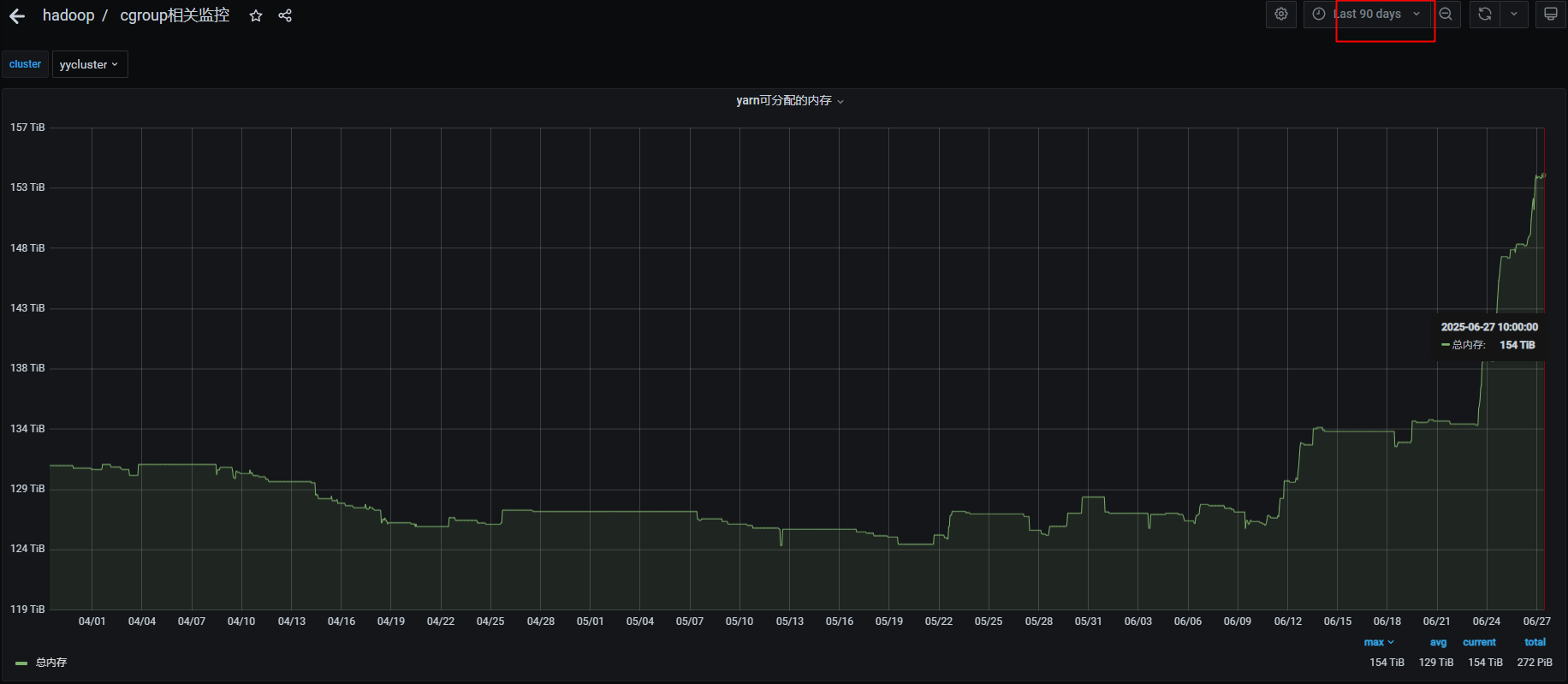
yarn可分配总内存提升20TB左右,当前对比90天历史数据
业务分配的内存对比,例:核心队列 当前分配内存也相对多了15%。其它队列一样提升15%

高峰期任务并行量增加,说明有更多的资源给到任务在跑
Yarn默认内存管理存在的问题
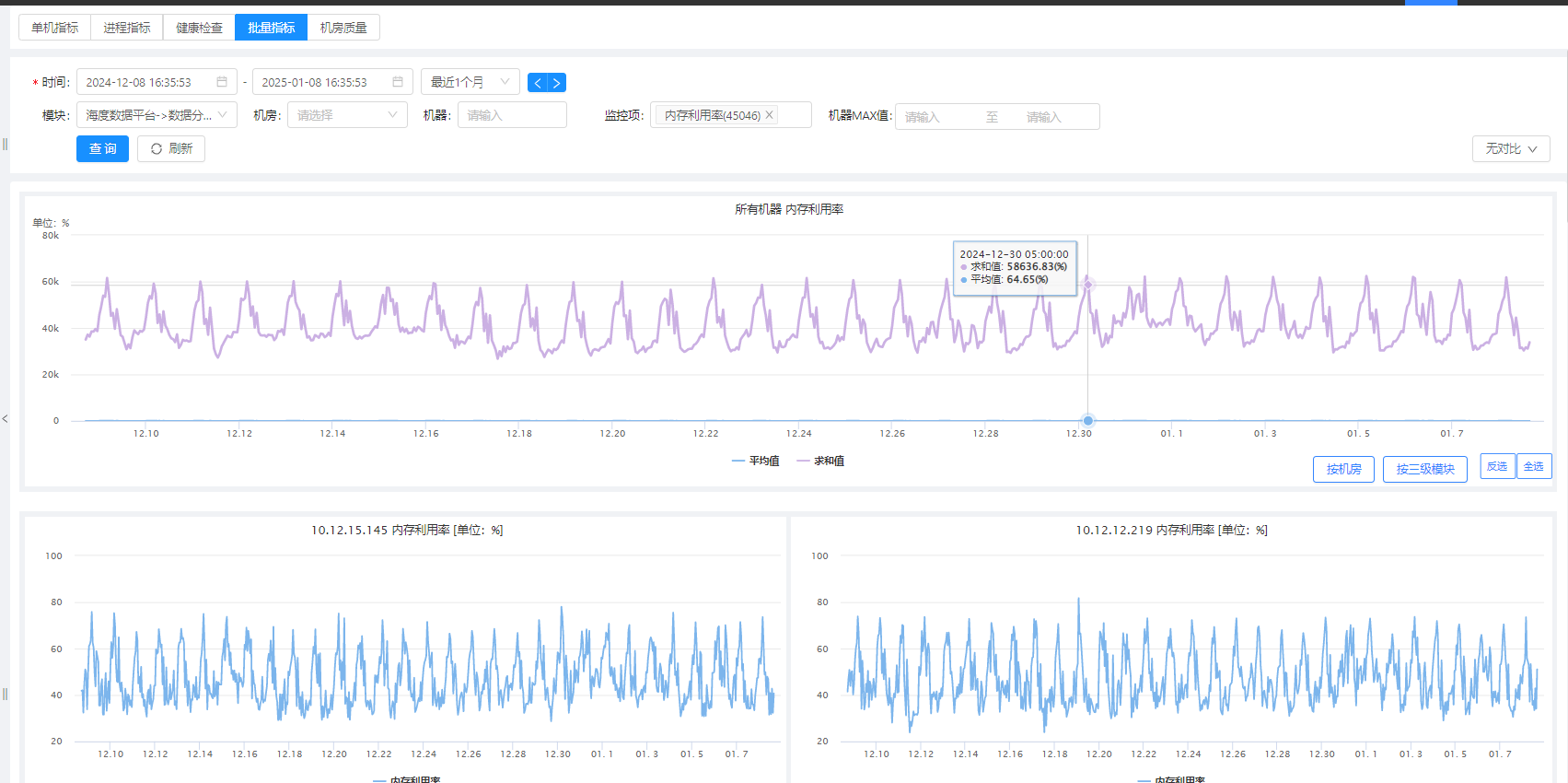
当前观察nodeManger物理机实际内存利用率,还存在一定的浪费(spark 在分配置内存的时候,实际jvm存在没有用满的情况),存在一定的内存碎片。
监控观查(可以在几秒内内存是可以用到100%利用率的)大约平均在60%-80%使用率。
测试验证
| 物理机 | 物理机内存(G) | nm分配内存(G) | 跑任务使用到100%(G) | 物理机内存利用率 | 系统预留 | 碎片浪费 |
|---|---|---|---|---|---|---|
| 10.12.66.1 | 125 | 100 | 100% | 28% | 10% | 50% |
| 10.12.66.2 | 125 | 100 | 100% | 28% | 10% | 50% |
| 10.12.66.3 | 125 | 100 | 100% | 28% | 10% | 50% |
| 合计300G |
用spark任务打满正常逻辑的分配内存
这里为了验证可观性,故意写了一个实际用内存很低的任务,但内存给的很高的情况下。
#这里我们指定了executor-memory 12G,实际每个executor的java进程内存开销很低
/home/liangrui/spark/bin/spark-submit \
--class com.aengine.spark.app.example.HdfsTest \
--conf spark.kerberos.access.hadoopFileSystems=hdfs://yycluster01,hdfs://yycluster02 \
--master yarn --deploy-mode cluster --executor-memory 12G --driver-memory 1G \
--queue lion --principal test-hiido2 --keytab /home/liangrui/test-hiido2.keytab --name HdfsTest \
--num-executors 5 /home/liangrui/spark/examples/jars/aengine-spark-3_2.jar hdfs://yycluster01/user/dev/0225-11m-d.json
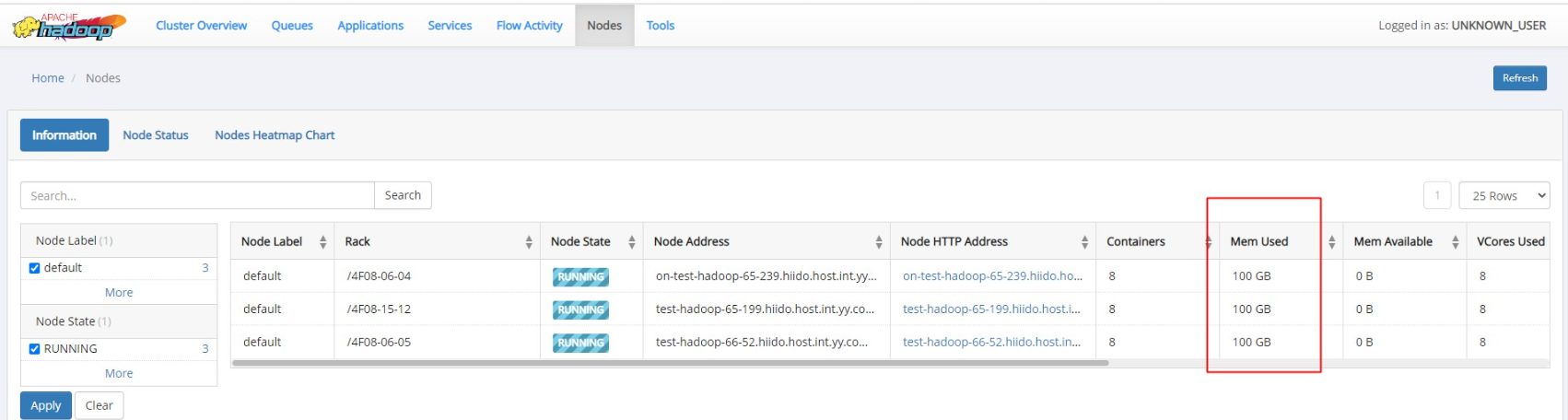
 yarn集群显示内存use 100GB,实际物理内只有28%的利用率,那么就有50%的内存存在碎片浪费
yarn集群显示内存use 100GB,实际物理内只有28%的利用率,那么就有50%的内存存在碎片浪费
解决方案
解决这个问题,需要开启yarn cgroup功能
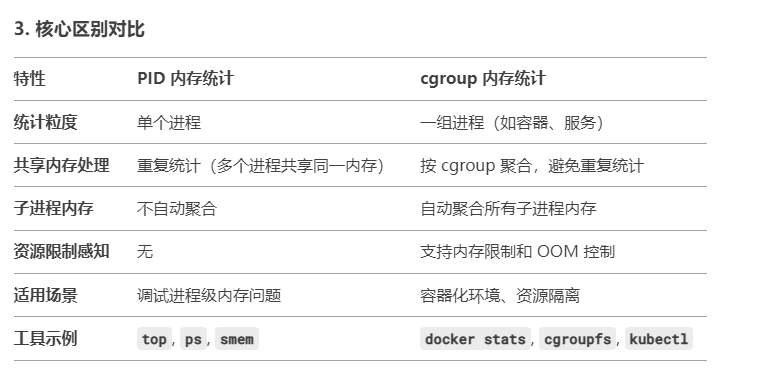
以下内容是DeepSeek给出的对比 问答主题:(linux pid 内存统计 vs cgroup内存统计)
实现方案
阶段一
我们当前hadoop版本是3.1.1,版本较低,YARN 3.2.0中使用内存弹性控制,需要把相关PR功能合并回3.1.1,具体合并内容
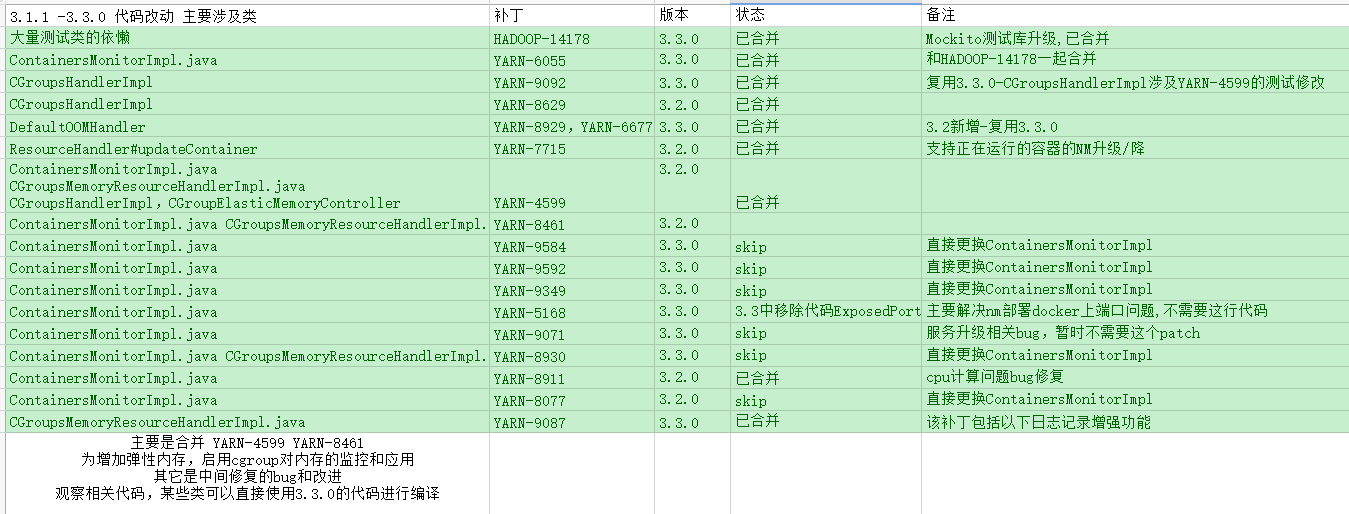
参考文档
cgroup文档: https://docs.kernel.org/admin-guide/cgroup-v1/cgroups.html
CGroups 与 YARN 结合使用: https://hadoop.apache.org/docs/r3.3.0/hadoop-yarn/hadoop-yarn-site/NodeManagerCgroups.html
YARN 中使用内存控制: https://hadoop.apache.org/docs/r3.3.0/hadoop-yarn/hadoop-yarn-site/NodeManagerCGroupsMemory.html
cgroup 内存溢出控制例子: https://docs.redhat.com/zh-cn/documentation/red_hat_enterprise_linux/7/html/resource_management_guide/sec-memory#memory_example-usage
阶段二
实现完阶段一功能后,在不开启任何配置,把jar包更新到集群中,验证合并代码是否正常,正常后进行阶段二配置优化。
但还需要以下改进
- 阶段一是直接调小每个作业的分配内存大小,来满足超卖内存的需求,这样改动范围较大,不好管理,因此在服务端调整nm分配内存和实际监控内存隔离。
- 触发实际物理内存oom-kill导致作业异常后,对作业产生异常需要有个兜底方案
- 调整jvm Xmx限制,目前spark的jvm xmx和executor是一致的,hive用的是mr参数,默认是mapre 4g和-Xmx 4000m。启用弹性内存后,可以放大此限制。
nm分配置内存和oom监控内存隔离
调试hadoop源码发现这里的逻辑可以实现分离配置
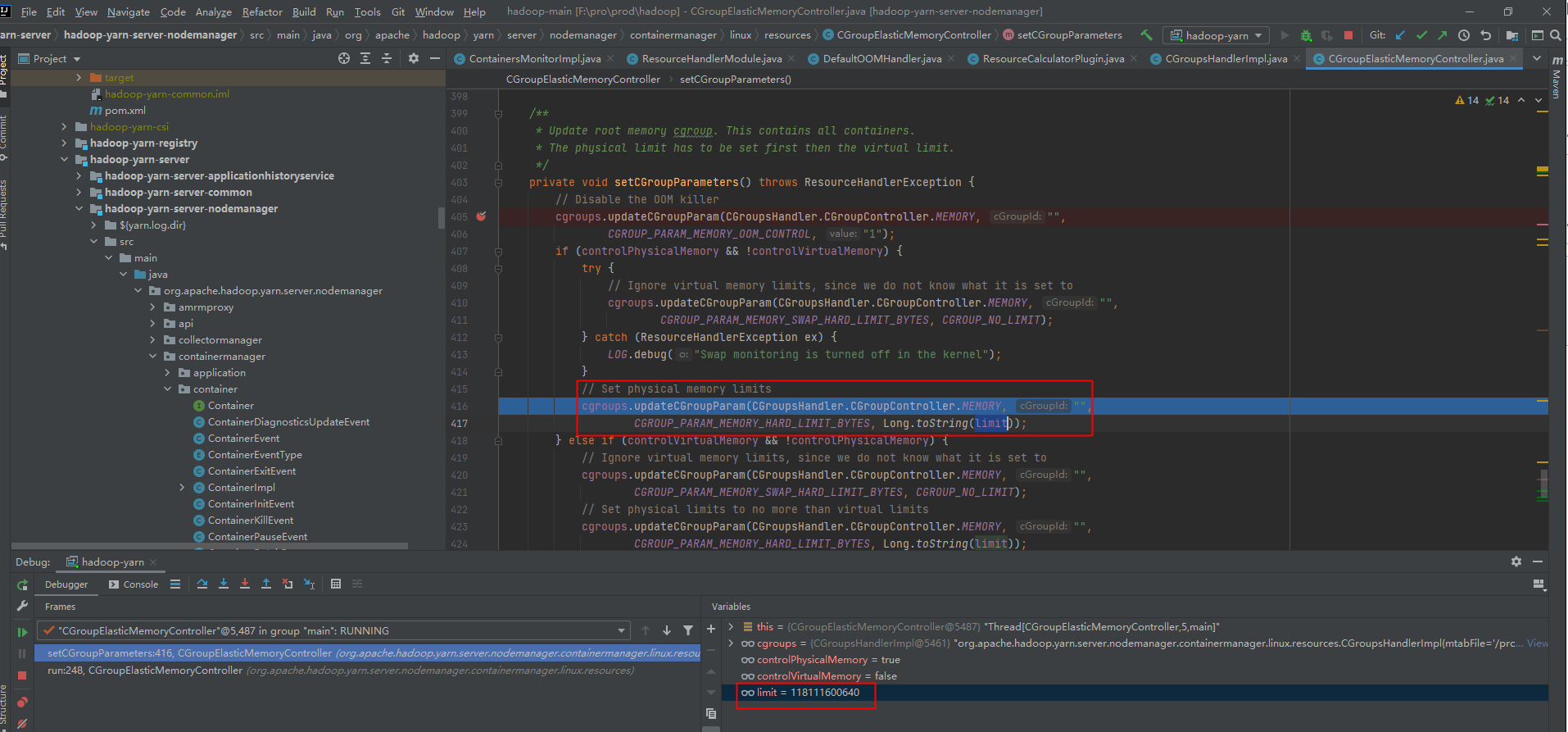
实际内存不足导致作业异常
存在集群把实际内存用完,但yarn认为还有内存可用,就会继续分配置作业给nm,这时候nm就会按kill掉container(按一定的顺序),直到nm有内存可以继续跑其它container。 例:一台yarn可分配110G内存,cgroup实际内存为88G=1100.80f hadoop jar /home/liangrui/spark/examples/jars/hdfs-client-op-1.0-SNAPSHOT.jar test.SleepMr hdfs://yycluster01/user/dev/0225-11m-d.json hdfs://yycluster01/user/dev/out/mr-0225-11m-d.txt 600 5 2048 10240m 参数:5个reduce5GB+内存开销,但yarn分配为5个reduce*2G内存,当cgroup内存开销到88G时,nm就会触发oom-kill,作业就会得到以下效果,container一直在被kill,一直在重试,只有AM不被kill掉就可以进行重试,直到有内存可以跑。
#MR AM默认重试2次
mapreduce.am.max-attempts=2
#YARN 服务端AM重试2次
yarn.resourcemanager.am.max-attempts=2
#spark AM重试1次,对应yarn am
spark.yarn.maxAppAttempts=1
#yarn service端配置,它们被服务 AM 替换
yarn.service.am-restart.max-attempts=20
yarn.service.container-failure.retry.max=-1 没有限制。
被kill掉的任务不算异常,但MR还有一种会导致异常,在总体实际内存超限的时候,作业内部其它进程,可能申请内存导致内存不足异常(在oom-kill处理的同时触发)。
例:这里只有一台nm的情况,并把nm可用的实际内存用满的情况:等于线上实际yarn可用实际物理内存用完的情况。也就是100%利用率的时候。
#客户端日志
25/03/19 14:44:35 INFO mapreduce.Job: Task Id : attempt_1742358710616_0001_r_000003_2, Status : FAILED
[2025-03-19 14:44:32.093]Container killed on request. Exit code is 137
[2025-03-19 14:44:33.682]Container exited with a non-zero exit code 137.
[2025-03-19 14:44:33.683]Killed by external signal
25/03/19 14:44:37 INFO mapreduce.Job: map 100% reduce 13%
25/03/19 14:45:01 INFO mapreduce.Job: Task Id : attempt_1742358710616_0001_r_000004_2, Status : FAILED
[2025-03-19 14:44:58.572]Container killed on request. Exit code is 137
[2025-03-19 14:44:59.356]Container exited with a non-zero exit code 137.
[2025-03-19 14:44:59.357]Killed by external signal
25/03/19 14:45:05 INFO mapreduce.Job: Task Id : attempt_1742358710616_0001_r_000001_2, Status : FAILED
[2025-03-19 14:45:02.436]Container killed on request. Exit code is 137
[2025-03-19 14:45:02.657]Container exited with a non-zero exit code 137.
[2025-03-19 14:45:02.658]Killed by external signal
25/03/19 14:45:12 INFO mapreduce.Job: map 100% reduce 100%
25/03/19 14:45:13 INFO mapreduce.Job: Job job_1742358710616_0001 failed with state FAILED due to: Task failed task_1742358710616_0001_r_000003
Job failed as tasks failed. failedMaps:0 failedReduces:1 killedMaps:0 killedReduces: 0
25/03/19 14:45:13 INFO mapreduce.Job: Counters: 40
#app master 日志
2025-03-19 14:45:10,145 DEBUG [IPC Server handler 24 on 29795] org.apache.hadoop.ipc.Server: IPC Server handler 24 on 29795: responding to Call#5
Retry#1 fatalError(attempt_1742358710616_0001_r_000003_3, org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: Error while doing final merge
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:160)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:377)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: org.apache.hadoop.fs.FSError: java.io.IOException: Cannot allocate memory
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.write(RawLocalFileSystem.java:262)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140)
at java.io.FilterOutputStream.flush(FilterOutputStream.java:140)
at java.io.DataOutputStream.flush(DataOutputStream.java:123)
at java.io.FilterOutputStream.flush(FilterOutputStream.java:140)
at java.io.FilterOutputStream.flush(FilterOutputStream.java:140)
at java.io.DataOutputStream.flush(DataOutputStream.java:123)
at org.apache.hadoop.mapred.IFile$Writer.close(IFile.java:158)
at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.finalMerge(MergeManagerImpl.java:759)
at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.close(MergeManagerImpl.java:379)
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:158)
... 6 more
Caused by: java.io.IOException: Cannot allocate memory
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:326)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.write(RawLocalFileSystem.java:260)
spark逻辑
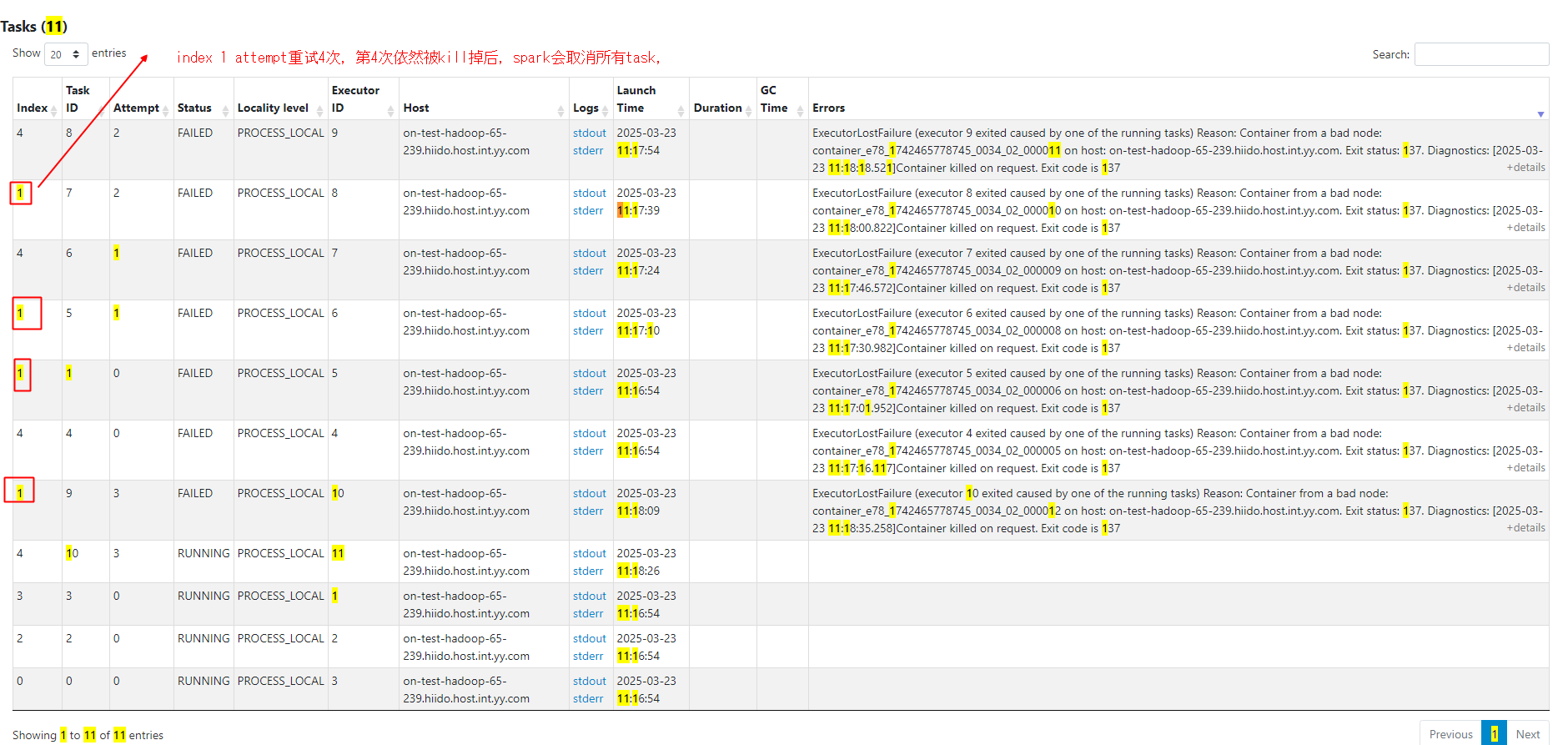
yarn在后台kill掉container后,spark会标记一次异常(以stage里的index为维度标记,一个index里重试4次(可配置,默认为4次)都为异常后,就会把作业标记为异常)。
例:只有一台nodemanger上跑spark,把cgroup可分配的内存量全部用完后,说明实际内存已用完,会触发yarn oom-kill机制。
 一样的作业内存开销为例,最后一个提交的saprk作业会异常,异常信息为:
# nodemanger日志
2025-03-23 11:17:02,348 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000006 killed by elastic cgroups OOM handler.
2025-03-23 11:17:16,514 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000005 killed by elastic cgroups OOM handler.
2025-03-23 11:17:31,400 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000008 killed by elastic cgroups OOM handler.
2025-03-23 11:17:46,987 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000009 killed by elastic cgroups OOM handler.
2025-03-23 11:18:01,190 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000010 killed by elastic cgroups OOM handler.
2025-03-23 11:18:18,931 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000011 killed by elastic cgroups OOM handler.
2025-03-23 11:18:35,678 WARN resources.DefaultOOMHandler (DefaultOOMHandler.java:killContainer(252)) - container container_e78_1742465778745_0034_02_000012 killed by elastic cgroups OOM handler.
# spark driver日志
Driver stacktrace:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 9) (on-test-hadoop-65-239.hiido.host.int.yy.com executor 10): ExecutorLostFailure (executor 10 exited caused by one of the running tasks) Reason: Container from a bad node: container_e78_1742465778745_0034_01_000012 on host: on-test-hadoop-65-239.hiido.host.int.yy.com. Exit status: 137. Diagnostics: [2025-03-23 11:16:35.969]Container killed on request. Exit code is 137
[2025-03-23 11:16:36.472]Container exited with a non-zero exit code 137.
[2025-03-23 11:16:36.473]Killed by external signal
.
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2454)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2403)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2402)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2402)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1160)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1160)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1160)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2642)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2584)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2573)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:938)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2214)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2235)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2254)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2279)
at org.apache.spark.rdd.RDD.count(RDD.scala:1253)
at com.aengine.spark.app.example.HdfsTest10G$.main(HdfsTest10G.scala:64)
at com.aengine.spark.app.example.HdfsTest10G.main(HdfsTest10G.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:737)
Task 0 in stage 0.0 failed 4 times, most recent failure: ,这里的failed 4是指index 1重试了4次,其它index也有失败但还没到4次,只有其中一个到4次上限就会全部异常
Flink引擎逻辑
https://nightlies.apache.org/flink/flink-docs-release-1.6/ops/deployment/yarn_setup.html
yarn.maximum-failed-containers = 默认=-n -n就是TaskManager 容器
例:./bin/yarn-session.sh -n 5 # 请求 5 个 TaskManager 容器 此时,yarn.maximum-failed-containers 的默认值即为 5。若失败容器数超过此值,YARN 会话将终止。
mr&spark task异常配置
#MR
mapreduce.map.failures.maxpercent=0
mapreduce.reduce.failures.maxpercent=0
#spark
spark.task.maxFailures=4
导致异常解决方案
1:如果这种异常大面积出现,就需要调小cgroup限制内存和yarn预分配的内存差距(yarn.nodemanager.elastic-memory-control.ratio),让预分配内存和实际内存更相近,让内存不能超卖太多。 2:启用yarn机会型作业,根据业务等级把不重要的队列设置为机会型作业(机会型:会预先分配并初始化作业加载,只是等内存运行,一但其它container释放内存后,立刻计算,但在内存不足的时候,会优先kill掉这个类型的作业)在一定程度上减少对正常作业出错的概率,并会加快作业运行完,还有个好处是: 例:把dap设为机会类型作业,在资源满的时候,会被正常作业kill掉,这样不用提心dap提交大任务,一直跑到晚上,占用晚上高峰期资源性况出现。
3:解决:在spark请求yarn容器的时候,增加一个计数器,但这个计数器只能以appid维度计数,不能做到task级别kill计数,tadk级别数据在spark内核中实现 也就是这个作业的task被kill到N次后,就强制后面所有的container请求自动升级为GUARANTEED,这样yarn就不会优先Kill这个作业,而是找超出内存的或时间后面起的container进行kill.避免作业异常。 以下是改动了saprk 源码实现,在被kill掉N次后,主动升级为GUARANTEED类型。
spark.task.oomKill.maxFailures=默认源码里指定到30次,可根据情况调大,之所有可以调到超4次,是因为把code 137剔除了 spark.task.maxFailures的计数
具体代码改动参考:https://issues.apache.org/jira/secure/attachment/13076601/spark-support-yarn-OPPORTUNISTIC.patch
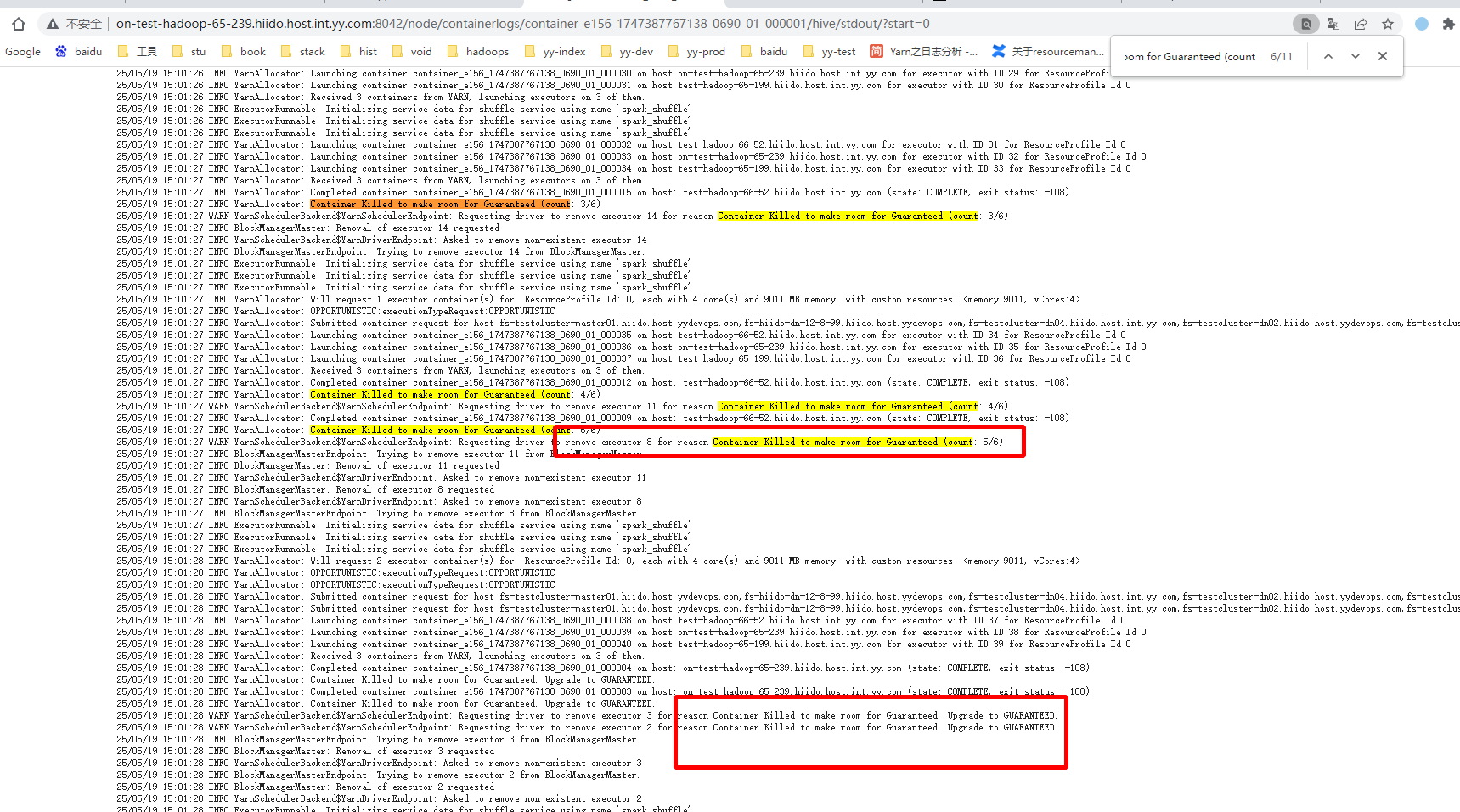 可以看到后面的类型已全为保证类型,不会优先被kill了。
可以看到后面的类型已全为保证类型,不会优先被kill了。
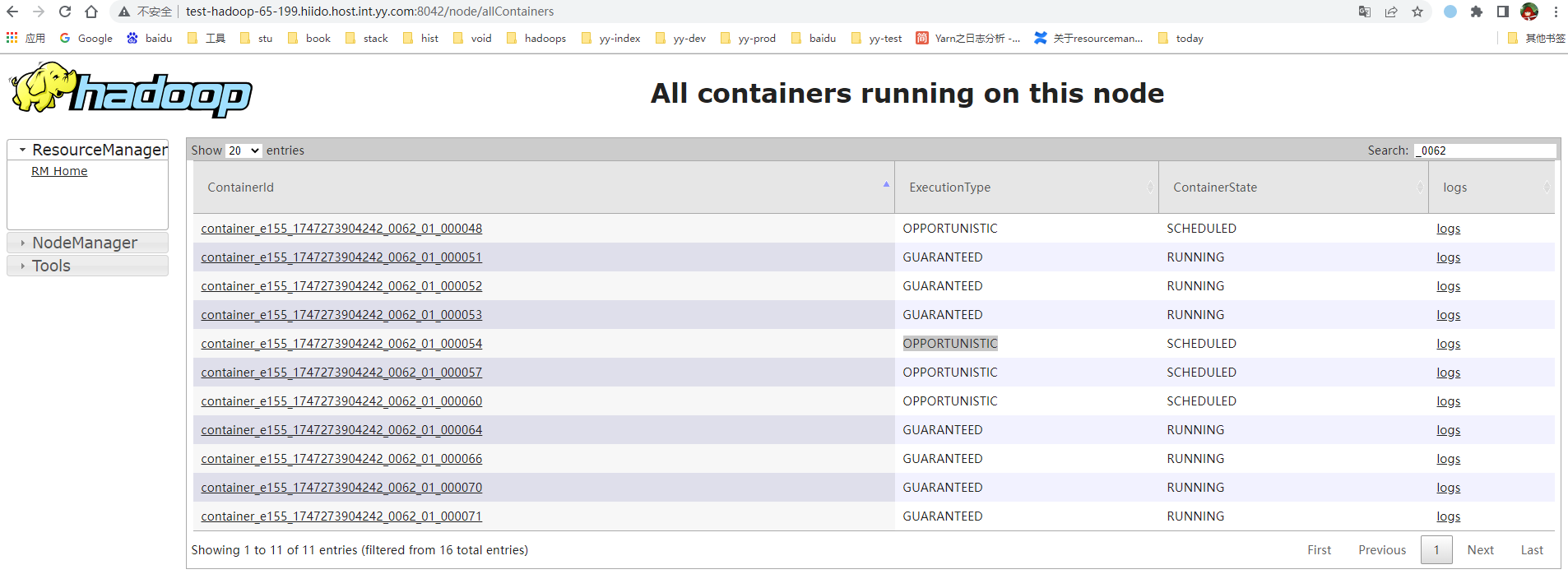
4:启用yarn机会型作业,根据业务等级把不重要的队列设置为机会型作业(机会型:会预先分配并初始化作业加载,只是等内存运行,一但其它container释放内存后,立刻计算,但在内存不足的时候,会优先kill掉这个类型的作业)在一定程度上减少对正常作业出错的概率,并会加快作业运行完,还有个好处是:
例:把dap设为机会类型作业,在资源满的时候,会被正常作业kill掉,这样不用提心dap提交大任务,一直跑到晚上,占用晚上高峰期资源性况出现。 Task 0 in stage 0.0 failed 4 times, most recent failure: ,这里的failed 4是指index 1重试了4次,其它index也有失败但还没到4次,只有其中一个到4次上限就会全部异常
 5:YARN层面优化
在触发cgroup oom-kill的时候,修改源码,判断container是否是master,非master的container才会被oom-kill,不然会导致作业失败
5:YARN层面优化
在触发cgroup oom-kill的时候,修改源码,判断container是否是master,非master的container才会被oom-kill,不然会导致作业失败
5:告警机制
- 增加cgroups ook-kill次数监控指标,在hadoop源码里增加,目前hadoop源码没有实现这个指标监控。可以及时发现超卖异常问题。
- 相关异常exit code作业异常告警,主要是13,137,内存问题导致加载类失败等异常